
The Vector Database Arms Race: Who's Really Winning the Developer Mind Share?
Analysis of over 13,000 pull requests shows why established search platforms may be outpacing purpose-built vector databases in the race for developer mindshare

The artificial intelligence boom has created an entirely new category of infrastructure: vector databases. These specialized systems store and search the high-dimensional vectors that power everything from ChatGPT's retrieval capabilities to recommendation engines at scale. But in a rapidly evolving market with both established players pivoting and new companies building from scratch, which approaches are actually winning developer mindshare?
We analyzed comprehensive GitHub data across major open-source vector database projects to understand real development momentum and community engagement patterns. The results reveal an interesting landscape where the new and shiny doesn't always win.
The Two Paths to Vector Search
The vector database ecosystem has crystallized around two distinct approaches.
Pure-play open-source vector databases like Milvus (founded in 2019), Qdrant (2020), Weaviate (2019), and Chroma (2022) were built specifically for AI workloads, with architectures optimized for similarity search and high-dimensional vector operations. These systems prioritize performance characteristics like sub-millisecond latency and petabyte-scale indexing without the constraints of legacy architectures.
Traditional search players and databases have taken the integration route, adding vector capabilities to established systems. Elasticsearch (2010) evolved from a search engine into a comprehensive AI infrastructure platform, while OpenSearch (2021), the AWS-backed fork of Elasticsearch, has developed its own vector search capabilities. Redis (2009) leveraged its in-memory architecture for real-time vector operations. MongoDB (2009) integrated vector search alongside its document model, and PostgreSQL (2010) enabled vector operations through the pgvector extension, allowing organizations to add AI capabilities without architectural changes.
The fundamental question these approaches raise is whether purpose-built vector databases will outcompete adapted general-purpose systems, or if the operational advantages of familiar technologies will prevail. But the real battle may already be decided by something far more powerful than technical superiority: which technologies are winning the hearts and minds of millions of developers who will ultimately shape the AI future.
Community Adoption: The Popularity Patterns
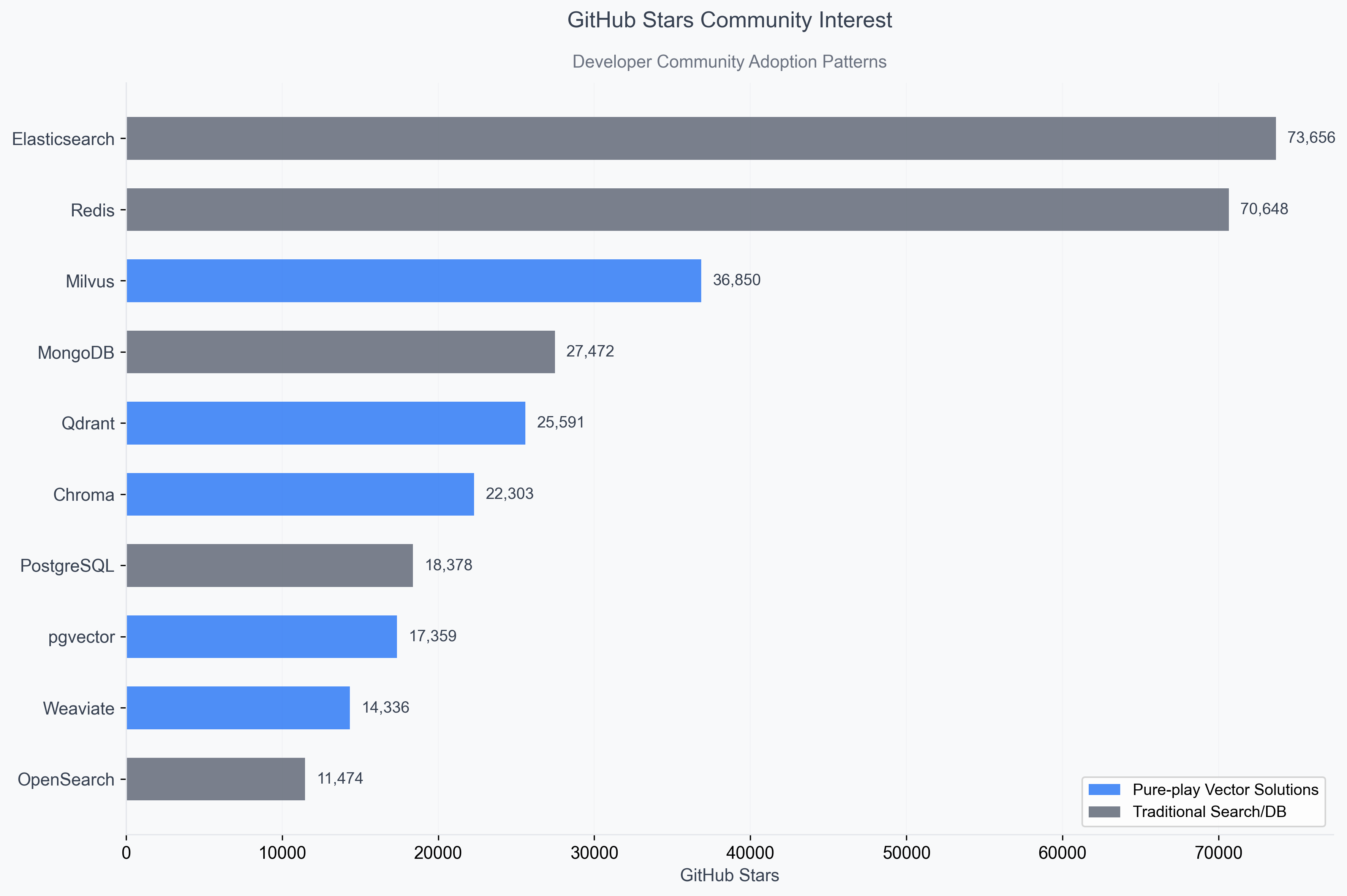
GitHub stars provide the first lens into developer interest patterns.
Elasticsearch dominates with 73,712 stars, followed closely by Redis at 70,731 stars, demonstrating the appeal of established systems.
However, the pure-play category shows remarkable momentum: Milvus has achieved 36,963 stars since 2019, surpassing MongoDB's 27,494 stars despite being a decade newer.
This pattern suggests that developers aren't simply defaulting to familiar brands when building AI applications. Instead, they're actively evaluating purpose-built solutions, with Milvus emerging as the clear leader among pure vector databases. Qdrant (25,705 stars) and Chroma (23,006 stars) also demonstrate significant community traction, indicating that the vector-native approach resonates with developers building AI-first applications.
The star distribution reveals a bifurcated market: traditional databases maintain their large existing communities while pure-play solutions rapidly build dedicated followings among AI practitioners.
Development Intensity: Where Innovation Actually Happens
In the GitHub world, while stars measure interest, pull requests (PRs) reveal where serious development work occurs. Our analysis of lifetime PR-to-star ratios—measuring cumulative code contributions relative to popularity since each project's inception—uncovers the real development intensity patterns across these platforms.
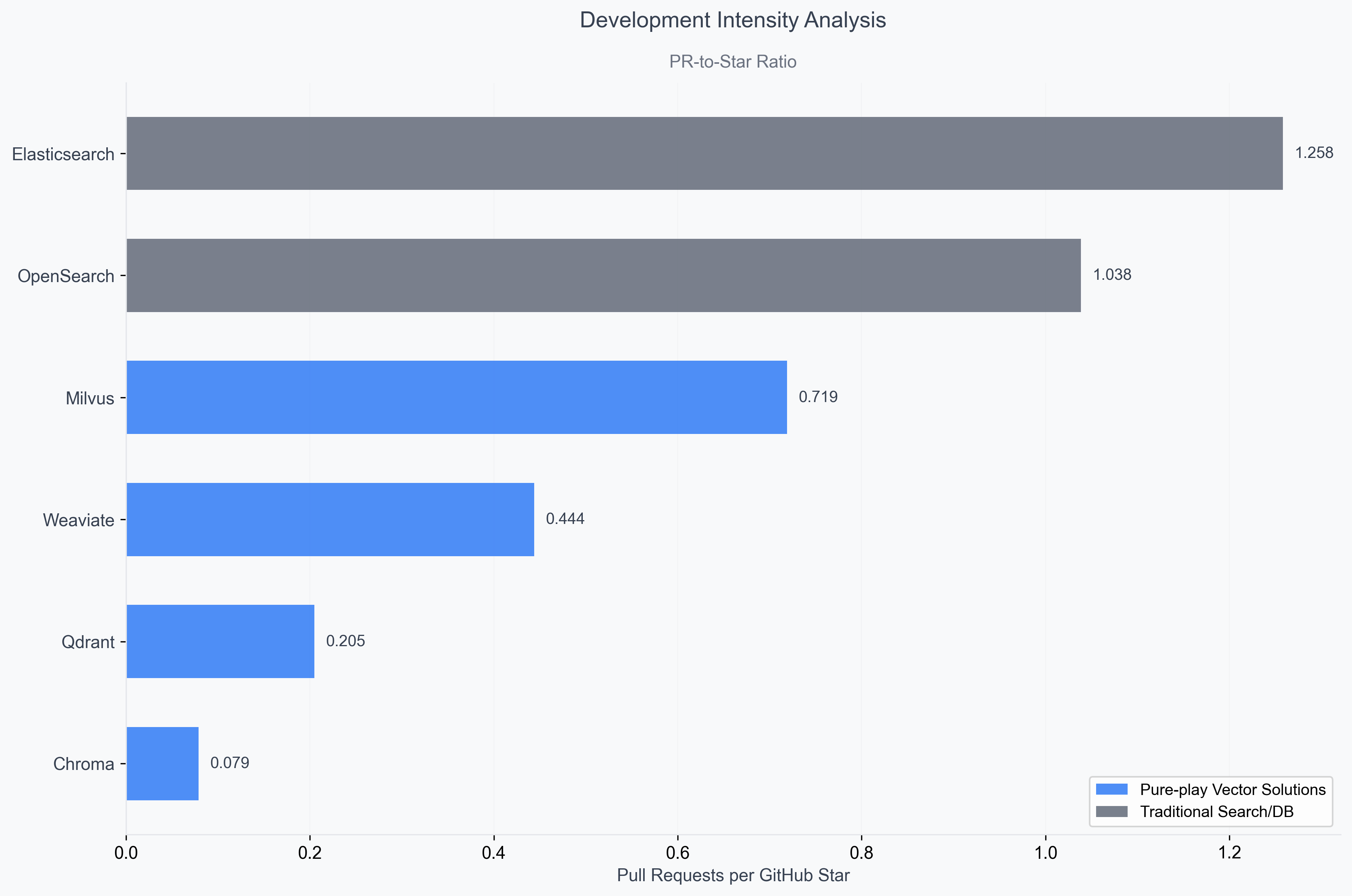
Elasticsearch emerges as an outlier with an exceptional development intensity ratio, indicating development activity that far exceeds typical open source projects.
Interestingly, Elasticsearch even maintains a significant development velocity advantage over OpenSearch despite both platforms sharing similar technical foundations, with Elasticsearch's 1.258 PR-to-star ratio substantially exceeding OpenSearch's development intensity, suggesting the original platform continues to attract greater engineering investment and community contribution activity.
Among pure-play databases, Milvus shows remarkable development intensity and sustained engineering commitment. Weaviate demonstrates strong development velocity, while Chroma, despite being the newest entrant, shows healthy recent activity.
One drawback to this analysis is that Elastic is a much broader platform (much beyond just vector search) and so the ratio might not be apples-to-apples when compared to pure-play vendors.
Development Momentum: The 2025 Reality
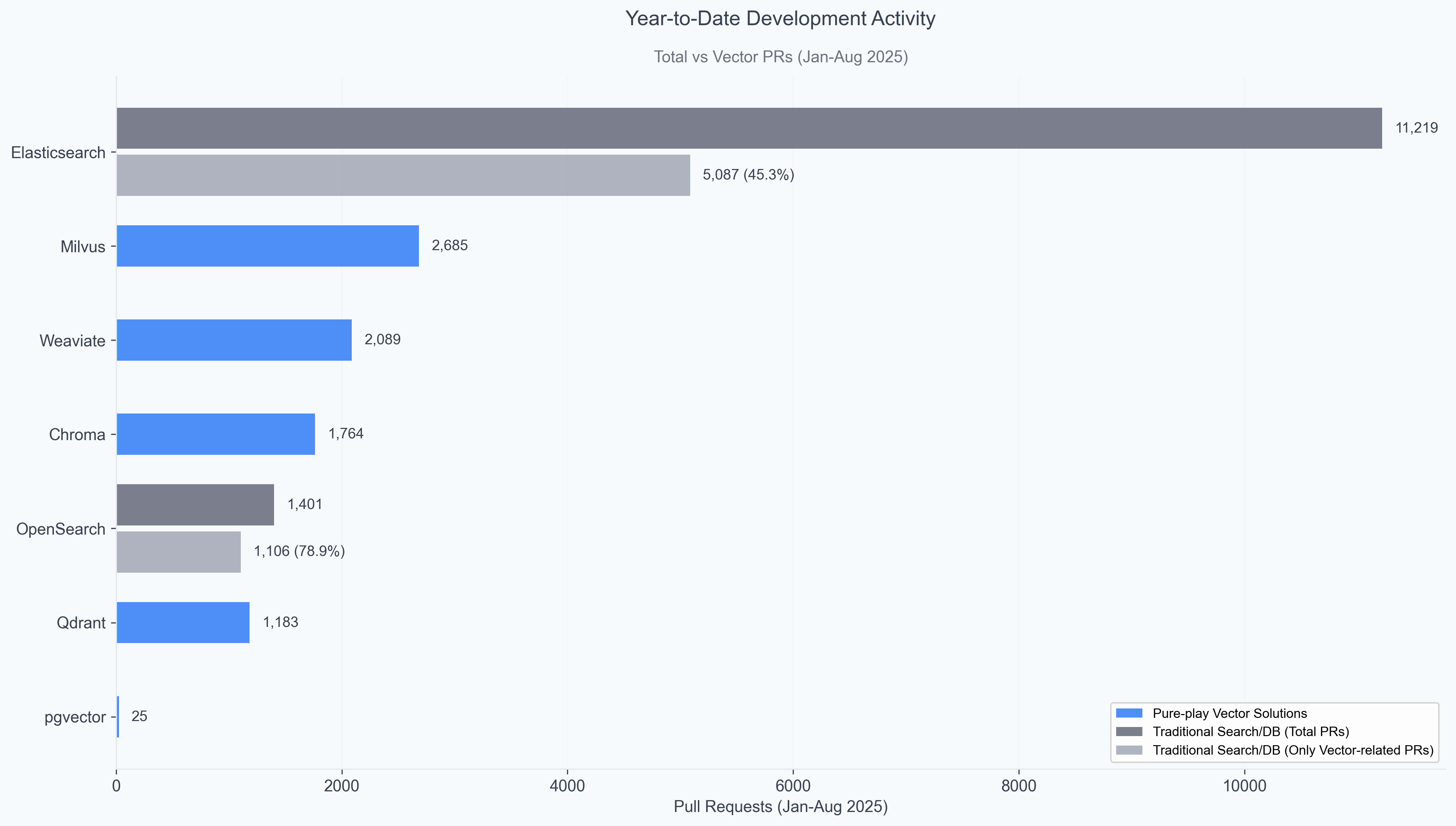
Year-to-date development patterns reveal sustained engineering investments across the vector database ecosystem.
Elasticsearch demonstrates remarkable overall development velocity with over 5K PRs related to vector search (11,219 total PRs) from January through August 2025. In fact it is the largest vector development effort in the ecosystem, demonstrating massive strategic investment in AI infrastructure capabilities
Milvus leads pure-play databases with 2,685 vector PRs, confirming its position as the most actively developed purpose-built vector database
Weaviate (2,089 PRs) and Chroma (1,764 PRs) show substantial development commitment among newer pure-play solutions, with Qdrant (1,183 PRs) following the pack.
OpenSearch (1,106 PRs) lags behind the lot, although shows a more focused development efforts, as almost 79% of all YTD PRs for OpenSearch was vector search related.
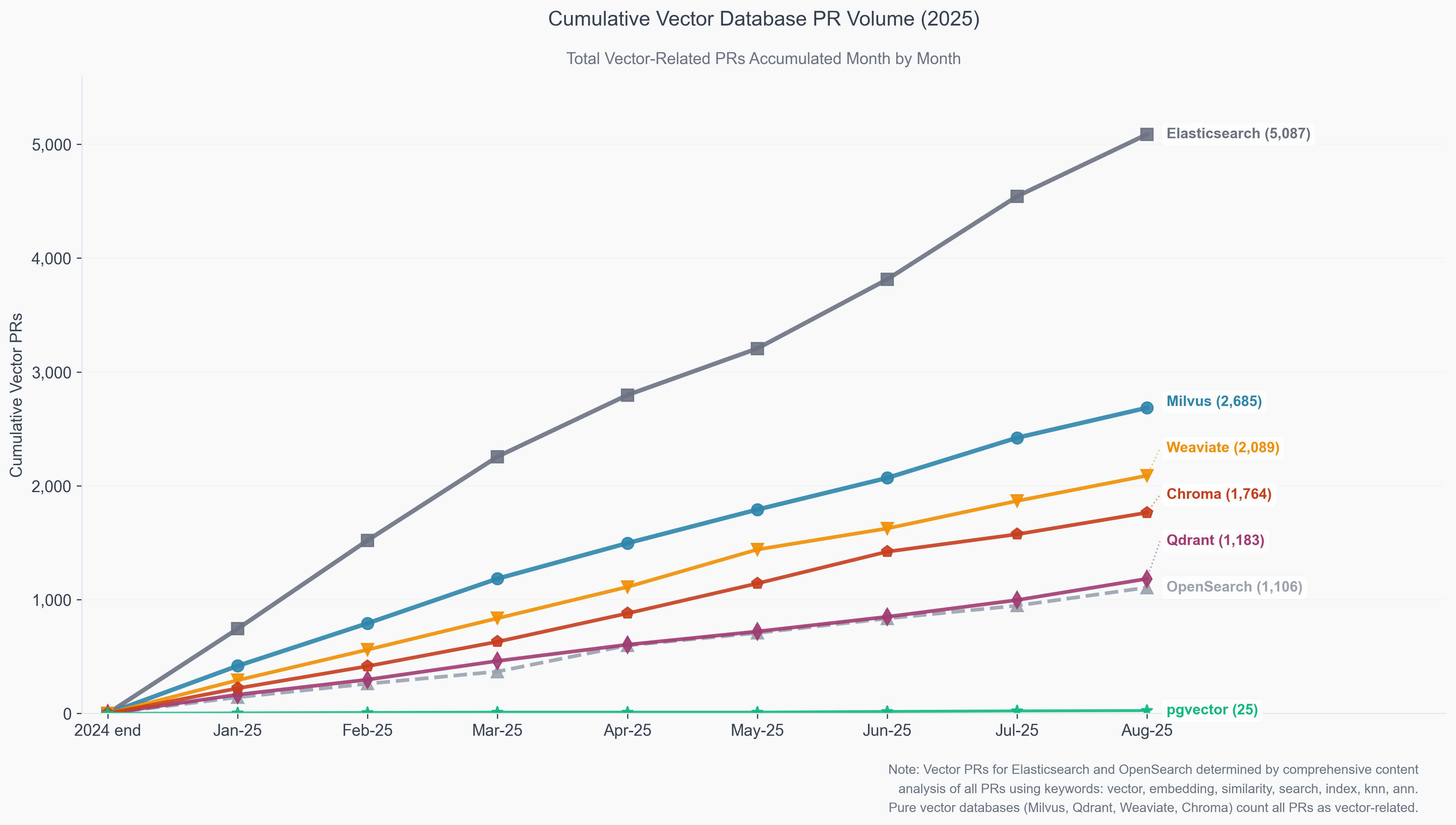
The cumulative vector development analysis (chart above) reveals the true scale of vector database engineering investment in 2025. This chart shows the remarkable scale of vector development activity, with massive cumulative volumes building throughout the year from January to August 2025. The total 13,914 vector-related PRs across all platforms in just 8 months demonstrates unprecedented engineering investment in vector database infrastructure throughout 2025.
Finally, an analysis of Elasticsearch's vector-related PRs reveals a strategic AI infrastructure transformation rather than simple feature additions. Of the 5,087 vector-related PRs, machine learning infrastructure dominates at 44.6% (2,270 PRs), followed by core vector operations at 22.1% (1,124 PRs), and approximate nearest neighbor search at 18.8% (956 PRs). The development timeline shows concentrated "AI sprints" during July-August 2025, with over 2,100 vector PRs in just two months, indicating coordinated platform-wide AI integration rather than incremental enhancements. This composition reveals Elasticsearch isn't just adding AI features—they're executing a complete platform metamorphosis that will fundamentally redefine enterprise search infrastructure.
Elastic’s growing vector search capabilities are also evident in the numbers, with the latest quarter indicating that roughly 10% of its total customers, including AI-native businesses, and ~21% of its customers spending over $100K in ACV with Elastic are using Elastic for Gen AI use cases.
“In Q1, we added more million dollar ACV Elastic Cloud customers using Elastic for GenAI use cases than the prior two quarters combined” - Elastic’s FQ1 (July) Earnings Call | August 28th 2025
The Bottomline
The GitHub data reveals a vector database landscape that defies simple narratives about incumbents versus newcomers. The 13,914 vector-related pull requests across all platforms in just eight months of 2025 represents an unprecedented level of ecosystem-wide innovation, but the concentration of development resources appears uneven. While pure-play solutions like Milvus have achieved impressive developer adoption and demonstrate the appeal of purpose-built architectures, the development intensity analysis suggests that established platforms with vector capabilities—particularly Elasticsearch—are making disproportionately large engineering investments that may be difficult for smaller players to match. The ultimate victor may not be determined by technical superiority alone, but by which approach can best navigate the tension between specialized performance and operational pragmatism as AI applications mature from experimentation to production scale.
Data Sources : GitHub Repositories (September 4, 2025)
Limitations of the Study
While this analysis provides comprehensive insights into vector database development patterns, several important limitations should be noted:
MongoDB could not be fully evaluated in our vector development analysis. MongoDB's vector search development appears to follow a private development model with limited public GitHub activity, despite the company's significant investment in vector capabilities.
This analysis focuses exclusively on public GitHub activity and may not capture development work happening in private repositories, internal corporate development, or other version control systems.
For traditional databases like Elasticsearch and OpenSearch, vector-related PRs were identified through keyword analysis. While comprehensive, this methodology may miss some vector-related work that doesn't explicitly mention vector terminology in PR titles and descriptions.
This analysis assumes continued importance of RAG and vector search architectures, but does not explore whether these technologies will remain central to AI applications.